The World's Leading
AI Model for Role-Playing
An Open API Platform with 220 Billion Parameters
Contact Sales
→
An Open API Platform with 220 Billion Parameters
24/7 Stable Availability
Supports High Concurrency Calls
Comprehensive Multi-Layered Security Protection
Enterprise-Level Data Security Assurance
Simple OpenAPI Calls
Rich and Detailed Integration Documentation
Continuous Stable Service
Multiple Disaster Recovery Guarantees

Easily Build Chat Ecosystems
Three Levels of Security Standards, Eliminating Risks




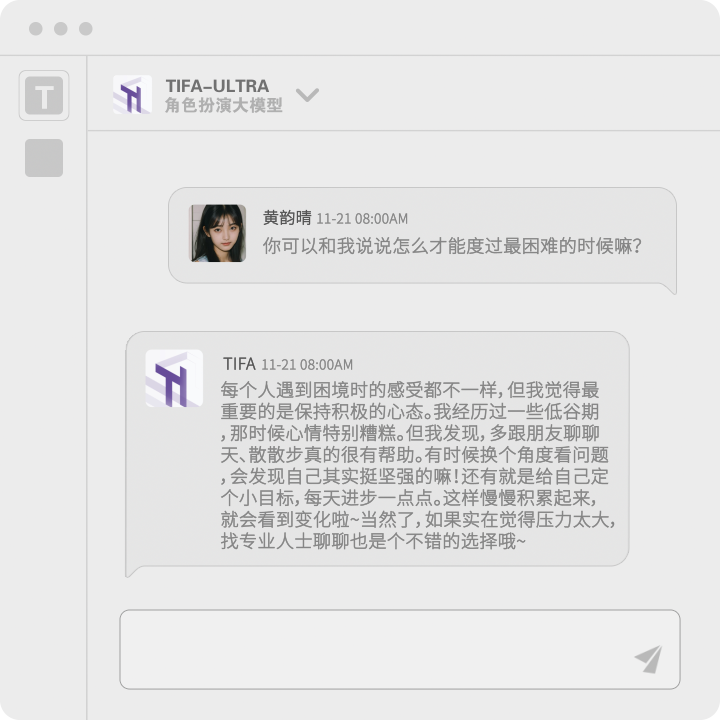
Tailored for Role-Playing
Large-Scale Pre-Trained Model, Rich Knowledge Base
Deeply Optimized Character Understanding and Expression
Long Text Understanding and Memory, Keeping Conversations Smooth and Natural
Accurately Capturing Emotional Details, More Engaging Responses
Comprehensive Comparative Evaluation, Strength at a Glance
Sampling: Our evaluation process involves comprehensive sampling of 100 interactions for each model across different domains and task types. These samples are carefully curated to represent a wide range of usage scenarios, including creative writing, problem-solving, multi-turn dialogues, and specific domain knowledge applications.
Evaluation Criteria: We have established a multifaceted evaluation framework that includes nine key areas of AI performance. Each criterion has specific scoring guidelines to ensure consistency in scoring across all models. These criteria are weighted based on their relative importance in real-world applications of AI language models.
Blind Testing: To eliminate bias, we implement a strict blind testing protocol. All model outputs are anonymized and randomized before being presented to the expert evaluation panel. This ensures that each interaction is judged solely on its merits, without any preconceived notions about the model's capabilities or reputation.
AI-Assisted Scoring: We employ an advanced AI scoring system to enhance human evaluation. This system is trained on a large dataset of pre-scored interactions to provide initial scores and highlight areas for human reviewers to focus on. AI scores are then verified and adjusted by human experts to ensure the accuracy and nuance of the final evaluation.
Statistical Analysis: Raw scores undergo rigorous statistical analysis to ensure reliability and validity. We use techniques like inter-rater reliability tests, confidence interval calculations, and standardization methods to account for potential biases or inconsistencies in scoring. The final scores represent the summary and statistical validation of this comprehensive evaluation process.
Reduce Costs and Increase Efficiency for Your Business
High Performance at Low Cost, Saving You a Significant Budget
Top-Tier Computing Power, Supporting High Concurrency Access
Optimized Inference Architecture, Providing an Ultra-Fast Experience
Multiple Disaster Recovery Backups, Ensuring Stable Service Operation
Trusted by Leading Enterprises














